Seeding Context in Personal Agent
Seeding Context in Personal Agent
Source Material
This is an X article I published about Suggested Context in Personal Agent.
A new conversation with your agent is either a time for new beginnings, or an annoying arduous task of re-populating the agent's context. A situation I've encountered one too many times is needing to re-seed a conversation with context.
Pi's built in forking feature is amazing for this. You never have to start a new conversation, just fork off the context of an existing one. However you do still need to maintain a conversation and continuously rewind to a specific point in time.
What if you could take advantage of existing conversations and not worry about manually maintaining the conversation's context?
I built a feature into Personal Agent called Suggested Context.
Suggested Context does exactly that, suggests past conversations for your agent based on what you type into the input box, then lets your agent use the context or not. Maybe I should have named it "suggested past conversations" but alas its too late now, I'm already writing this post.
How it works
When you start a new conversation, Personal Agent searches your recent conversation history for threads that might be relevant to what you're working on. If it finds good candidates, it injects a small pointer block into the agent's context at the top of the prompt — before you've sent a single message.
Pointer block injected into your context, not full conversations!
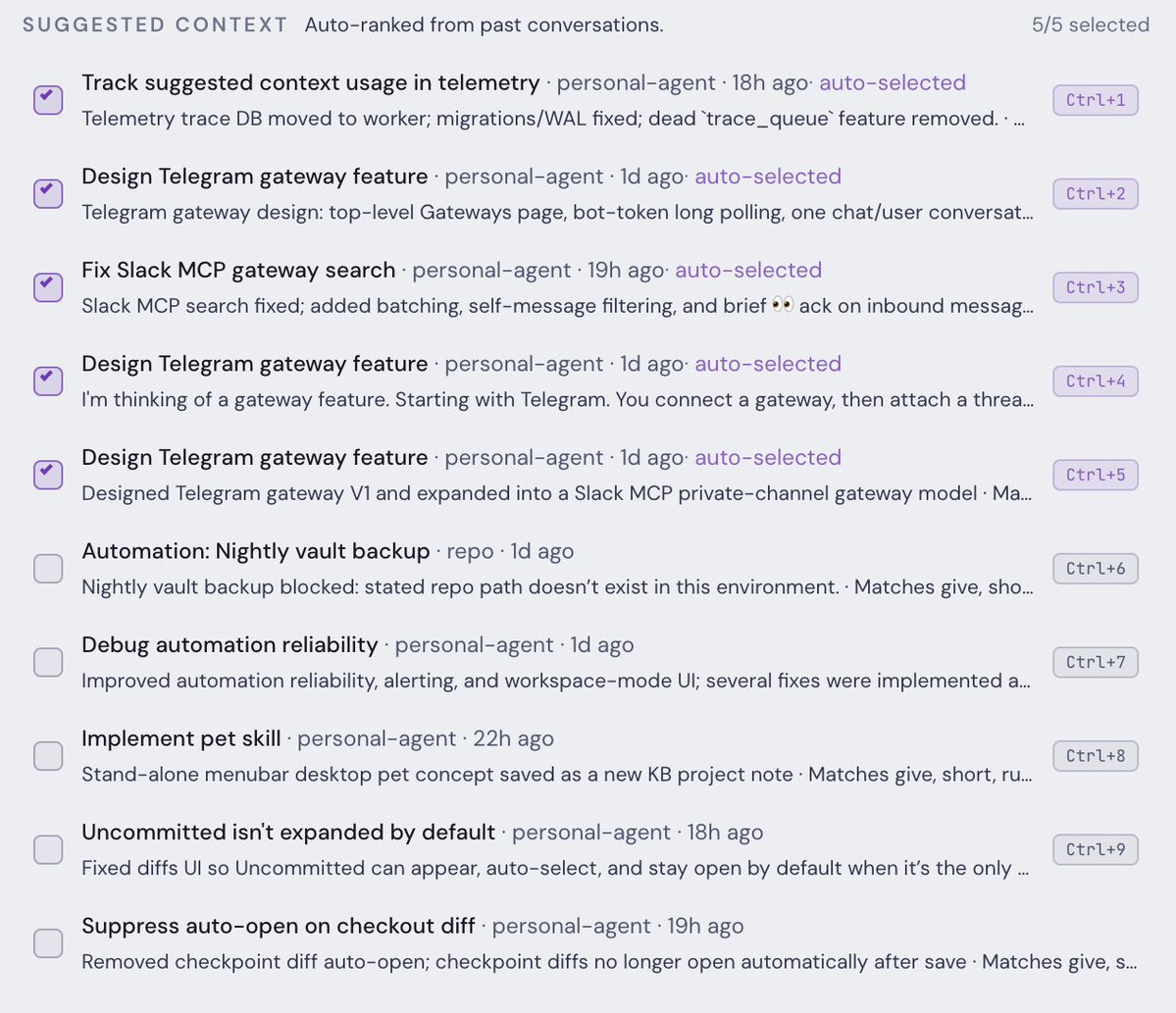
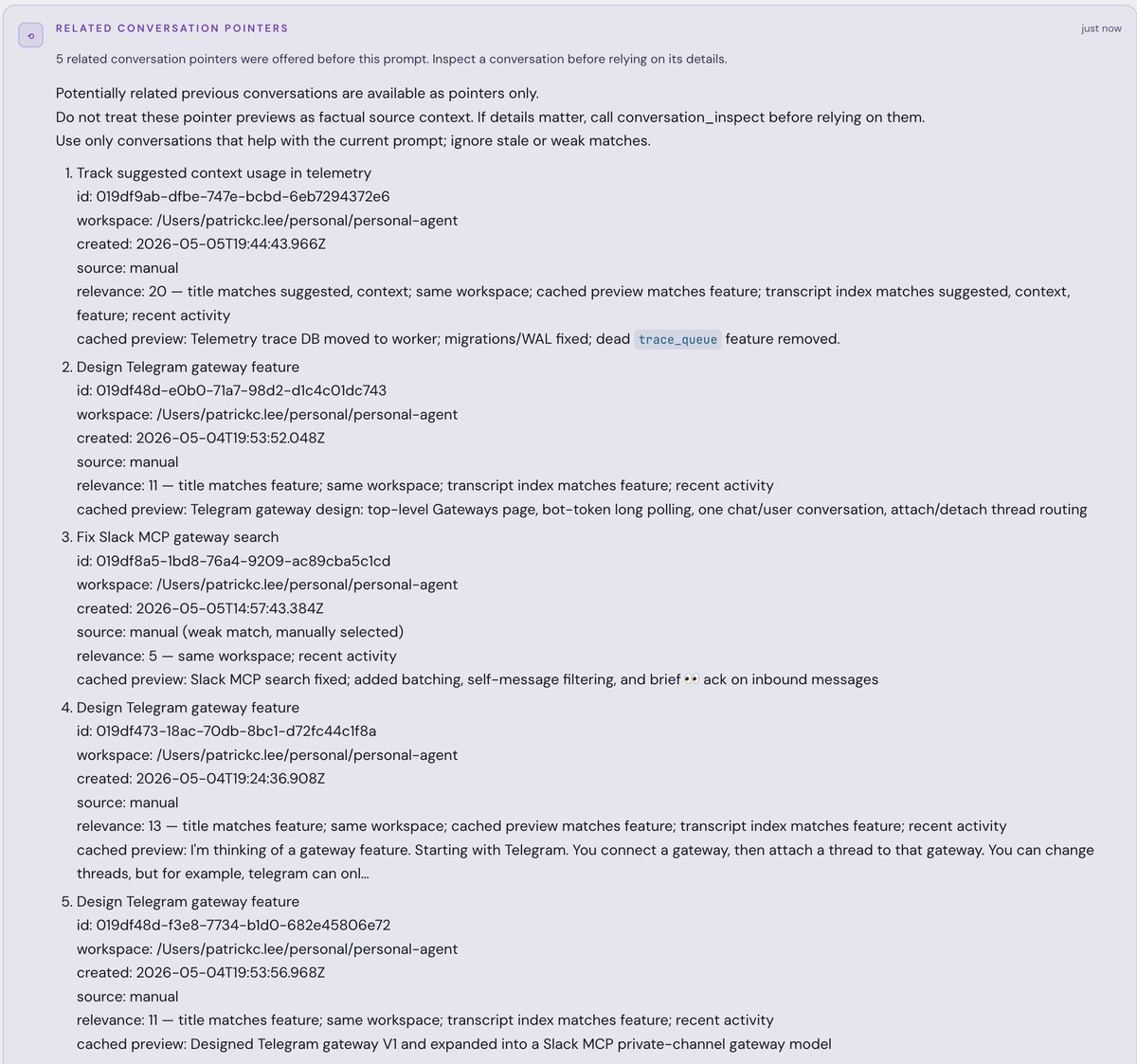
The agent gets the title, conversation ID, workspace, relevance score, the signals that drove the score, and maybe a short cached preview from the conversation's generated summary. That's it. No full transcripts. No walls of old text. If the details matter for the current task, the agent is expected to call conversation_inspect on the conversation and poke around the transcript.
This strategy is the same that skills use, providing a minimal pointer for the agent to follow if it needs to know more.
The scoring
Scoring is intentionally simple. Each candidate conversation gets ranked on a small set of signals:
- Title match: +5 per matched term, capped at +12
- Same workspace/repo: +3
- Summary or cached preview match: +2 per matched term, capped at +8
- Transcript search index match: +1 per matched term, capped at +6
- Recent activity (< 7 days): +2
- Recent-ish activity (< 30 days): +1
Auto-surfaced candidates need to clear a minimum score of 6 to be included. The list is capped at 5 pointers, sorted by score, then by most recent activity.
I am very explicitly not doing semantic retrieval here. There's no embedding lookup, no cosine similarity, no vector database. Just stop-word filtered term matching against titles, workspace paths, generated summaries, and a pre-built search index. Similarity search is slow and expensive and requires chunking and embedding conversations.
The tool use side
When the agent actually wants to use a suggested conversation, it calls conversation_inspect. This tool lets your agent query the real transcript by searching blocks, filtering by role, reading windows around specific content.

This saves context by forcing the agent to probe conversation transcripts on its own rather than trying to generate relevant chunks of information like in more traditional RAG systems.
Does it work?
I just added telemetry so I need to collect more data, but initial results show it does get some use. Whether its actually useful or not is to be seen.
Seeding Context in Personal Agent
A new conversation with your agent is either a fresh start or an annoying exercise in re-populating context. I've hit this wall too many times.
Pi's built-in forking feature helps—you never start from scratch, just fork off existing context. But you still need to maintain conversations and continuously rewind to specific points in time.
What if you could leverage existing conversations without manually managing context?
I built a feature called Suggested Context.
It suggests past conversations based on what you type into the input box, then lets your agent decide whether to use them. Maybe "suggested past conversations" would have been a better name, but it's too late now.
How It Works
When you start a new conversation, Personal Agent searches your recent history for relevant threads. If it finds good candidates, it injects a small pointer block into the agent's context at the top of the prompt—before you've sent a single message.
Pointer blocks, not full conversations.
The agent gets the title, conversation ID, workspace, relevance score, the signals that drove the score, and maybe a short cached preview from the generated summary. That's it. No full transcripts. No walls of old text. If details matter, the agent calls conversation_inspect to poke around the transcript itself.
This mirrors how skills work: provide a minimal pointer for the agent to follow if it needs more.
The Scoring
Scoring is intentionally simple. Each candidate gets ranked on a small set of signals:
- Title match: +5 per matched term, capped at +12
- Same workspace/repo: +3
- Summary or cached preview match: +2 per matched term, capped at +8
- Transcript search index match: +1 per matched term, capped at +6
- Recent activity (< 7 days): +2
- Recent-ish activity (< 30 days): +1
Candidates need a minimum score of 6 to surface. The list caps at 5 pointers, sorted by score, then by recency.
I'm explicitly not doing semantic retrieval here. No embedding lookup, no cosine similarity, no vector database. Just stop-word filtered term matching against titles, workspace paths, generated summaries, and a pre-built search index. Similarity search is slow, expensive, and requires chunking and embedding conversations.
The Tool Use Side
When the agent wants to use a suggested conversation, it calls conversation_inspect. This tool lets it query the real transcript—searching blocks, filtering by role, reading windows around specific content.
This saves context by forcing the agent to probe transcripts on demand rather than trying to generate relevant chunks upfront like traditional RAG systems.
Does It Work?
I just added telemetry, so I need more data. Initial results show it does get use. Whether it's actually useful remains to be seen.